“Serverless computing is a cloud computing execution model in which the cloud provider allocates machine resources on demand, taking care of the servers on behalf of their customers.”
A recent uninformed discussion on Linkedin about container orchestration (wrongfully) compared to serverless, sparked a few thoughts in my mind:
- How well do I understand what a serverless function is?
- What does this mean for developers in my team that run code exclusively on AWS Lambda?
- Does knowing the environment make any difference?
It is my intention in this post to answer these questions, given that (3) is obvious to me; I have to understand the environment in order to make informed decisions. In addition, I assume that in regards to question (2), if I didn’t have the time to dig deeper, many of my colleagues didn’t either, so this may be my way of sharing what I’ve learned with them.
The benefits and drawbacks of Serverless functions
Pros:
- Speed of development - using frameworks like serverless.com (deserves its own blog post), development speed is increased exponentially. All resources are easily deployed, connected to the network, protected by permissions and security groups, as well as a lot of other features. It can relieve DevOps / production engineers of the burden of managing moving parts, and allow developers to operate independently on their own terms, eliminating bottlenecks. Obviously, this isn’t magic, and “Managed correctly” is key here, templates and boilerplates, coupled with least privilege access will go a long way towards ensuring speed is not sacrificed for security or control.
- Scale - as Lambda is a service that runs packaged code, it can (theoretically) scale infinitely, only limited by AWS’s own limitations, which are considered close to infinite in most use-cases. It scales quickly and automatically. Even though it may come at a price, both in terms of service and cold starts, if the volume is monitored, it can be planned accordingly to maximize speed and efficiency (see “Handling cold starts” above).
- Security - The Lambda function, as noted, runs a number of seconds on its own infrastructure before going to “sleep”. In that sense, it is more secure because it can only be accessed through AWS’s API, and cannot be accessed in any other way. On the other hand, containers are usually accessed through an attached shell. When a malicious actor has access to an internal system, it becomes a possible attack vector. In this sense, Lambda functions are inaccessible, even when attached to a VPC. In addition, there isn’t an underlying infrastructure like K8s or ECS nodes to run, so one fewer layer needs to be protected.
- Efficiency - Lambda functions run for the required amount of time and then hibernate (or completely shut down the environment) until the next run. This provides maximum efficiency. Infrastructure is only paid for by the number of seconds it takes to process data, nothing more, nothing less. There is no billing for “dead” time. This drives constant improvements to reduce runtime. It can be achieved by using message queues, caching layers, or simply by improving the application’s performance. It is a pleasant side-effect with a positive impact.
Cons:
- Price - Lambda functions are not cheap. AWS offers a generous free tier, but lambdas can grow to be a major part of an AWS cloud bill after a certain point. There are many solutions to this problem, such as offloading certain components to containers or instances, and improving performance. However, this is one of the most important factors to consider when making the decision.
- Speed - also listed as a pro, speed the speed at which developers can deploy new infrastructure can get out of hand. It is something to consider when allowing the whole engineering team to use their networking and security components for production functions.
- Distribution can be an obstacle - Lambdas are best when they are distributed; when the code is divided into small parts, each with one logical purpose, rather than a few. This allows them to respond, scale and operate as fast as possible. At the same time, it can be difficult to keep everything under control. Monitoring, CI pipelines, and infrastructure become increasingly challenging to track, monitor and manage as the number of them grows.
What is it
Serverless functions are a way to run code in a distributed, scalable and efficient manner in a cloud environment.
A key feature is the ability to write code and “throw” it to the cloud, where some “magical” system runs it, preparing an environment and billing the user for the runtime seconds and resources used.
Under the hood
AWS Lambda runs code in a “runtime environment”, which is a containerized environment that holds everything the application needs. Dependencies, layers, and files are all prepared and loaded onto an AWS-shared infrastructure. This is done in an isolated, secured way so that neighboring functions are not exposed in any way to the other “environments”.
“Cold start” is the process of setting up a container and preparing it for a Lambda function, then running it for the first time. Imagine calling a function in a simple application you wrote, but each time it’s called, the application starts and then stops. The process is of course inefficient in the sense that it runs longer, but it is extremely more efficient considering the time a certain piece of code is not called, and therefore, is not billed.
This is not a straight forward process at all; certain questions must be asked:
- How often is this piece of code called on a minute, hour, or daily basis?
- How long does it take for the function to complete its run?
- Could the function end faster? (hint: yes, it sure can!)
- How crucial is responsiveness?
- Is latency something we’d like to pay extra for, or keep as low as possible?
- Assuming serverless is the way to go for our engineering team, but mainly in terms of speed, is the cloud the most suitable option for us?
Let’s try to answer a few of these questions to make architectural decisions:
What is the frequency of calling the function?
If the answer is thousands of times a minute, perhaps a provisioned concurrency is worth considering. If the function is not being called all that often, perhaps it’s wise to use a lambda warmer to keep it warm - see dealing with cold starts below.
How long does it take for the function to run?
The best practice is to have functions operate on a single logical unit, having the smallest possible task to take care of. This will result in a short running time and a more distributed system that can scale and start up quickly. An option to consider is wrapping a “long running” function with supporting services to speed up its execution. A “long” run time can range from seconds to minutes. Examples for solutions are - utilizing queues and additional functions instead of sending a request and waiting for a response. Another option is the use of a cache mechanism to provide faster responses from data services. In the end, if a function still takes minutes to run, even with all the support and efficiency improvements, it may be a candidate for a live service. Maybe a job that runs in a container and terminates, or a full-fledged service running on K8s, or ECS. In either case, serverless is not a one-size-fits-all solution.
Is the cloud really the best choice?
When the goal of serverless is purely functional, i.e. making it easier for developers to work productively and deploy infrastructure quickly, a PaaS might not be the best option. Not because of features, but because of price, and in some cases, high latency when working against internal tools like databases and secret managers. Knative and Fission are two alternatives. As I don’t have real experience with these, I cannot comment on their capabilities. However, I can say they might hold some of our production serverless deployments in the future.
Key takeaway: “Serverless is not a one-size-fits-all solution”
A deeper look into networking
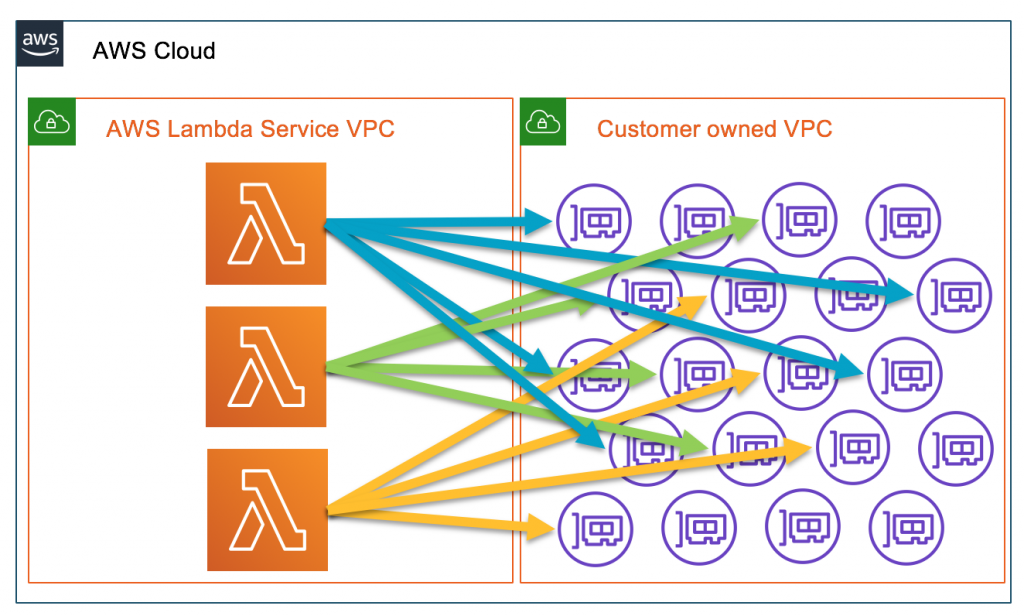
The functions run on an “AWS shared infrastructure”, as mentioned earlier. The shared environment here is an AWS VPC dedicated to Lambda. Functions are invoked through the Lambda API (and only through it) in the VPC, where they can access the public internet, but cannot access neighboring functions or the owners’ private network (that’s you).
A function must be connected to the internal VPC in order to gain access to private subnet resources, such as databases, internal API services, and other supporting components. This does not mean the function runs inside the VPC, rather it has access to it via:
- Creating a cross-account attached interface
- Attaching and using the network interface from the user’s VPC to access resources
A recent improvement to this network scheme
Lambda functions in a VPC used to be somewhat problematic, in that a user had to consider:
- Creating and attaching the network interface requires a longer cold start
- Keeping an eye on rate limits pertaining to the number of network interfaces in a user’s VPC
- Limits on the number of available IP addresses for attached interfaces should also be considered
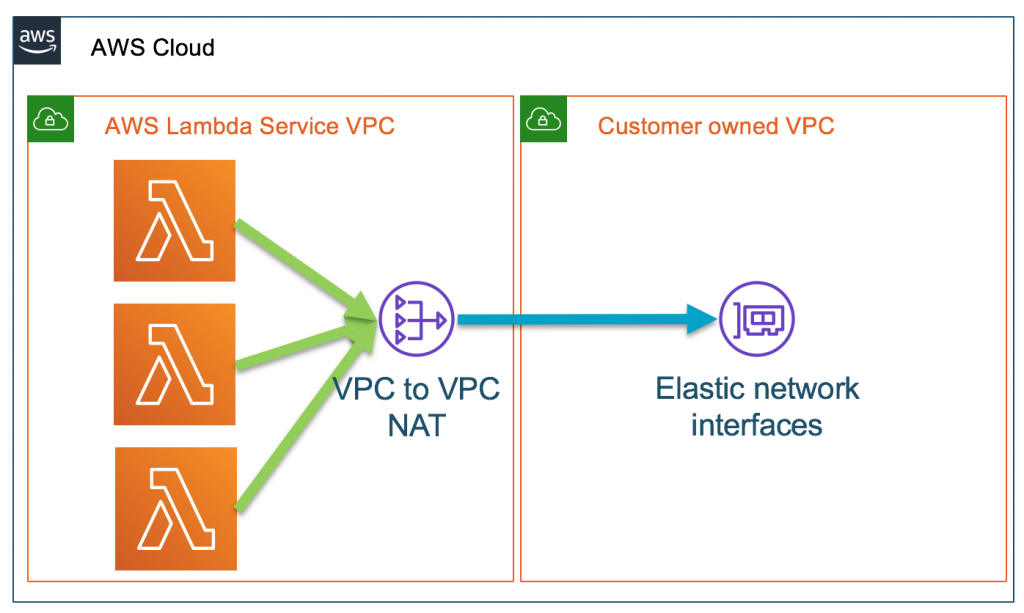
The above has been dramatically improved in 2019, when AWS announced an improved networking for Lambdas. Since then (and gradually in additional regions), Lambda functions started reusing a “Hyperplane ENI”, essentially allowing network interface reuse.
Because the network interfaces are shared across execution environments, typically only a handful of network interfaces are required per function. Every unique security group:subnet combination across functions in your account requires a distinct network interface. If a combination is shared across multiple functions in your account, we reuse the same network interface across functions.
- AWS “Improved VPC networking for AWS Lambdas” announcement, 2019
Here’s a diagram from AWS, explaining the change visually, this is the “old” networking scheme for VPC-attached functions:
Vs the new networking model, where a shared ENI is used:
Dealing with cold starts
While you do not pay for the time it takes to start a container, it adds to the overall latency of the end user’s experience. This may be of little importance in some use cases, yet critical in others.
There are several ways to combat cold starts:
- Warm up your lambdas with a lambda warmer. A warmer is essentially an external component that sends a ping to the function to initiate it and waits for a response. The key here is its repetitiveness and mimicking of customer-like behavior. It is recommended to do the following:
- Wait at least five minutes each time.
- Trigger the function directly to keep the same environment warm rather than trigger another one, which is typically the case when the trigger is coming through an API gateway
- Wait for a response, preferably one that’s prepared in the function specifically for warmers
- Send a test payload
- Further read this great post
- Use provisioned concurrency - a way to pre-configure the number of desired environments that are kept warm for the customer. Despite being on the more expensive side, this solution “magically” solves the problem of cold starts to some extent. However, cold starts also occur when:
- Updated version is introduced (code and configuration are the same for Lambda)
- All provisioned concurrency is used and another incoming request is waiting
- The platform automatically re-balances availability zones deployments
-
Make sure functions attached to a VPC and using the same subnet share a security group. In this way, no latency is introduced when creating and attaching network interfaces, since they can use an existing ENI:
Hyperplane ENIs are tied to a security group:subnet combination in your account. Functions in the same account that share the same security group:subnet pairing use the same network interfaces. This way, a single application with multiple functions but the same network and security configuration can benefit from the existing interface configuration.
- AWS “Improved VPC networking for AWS Lambdas” announcement, 2019
- AWS “Improved VPC networking for AWS Lambdas” announcement, 2019
Serverless isn’t always the best solution
The “cons” list above shows that running cloud functions can be challenging in some cases, and they may not always be the best solution. Aside from its usually high price, its features are good for some use cases and terrible for others. Combining functions with orchestrating containers seems to work well in my experience.
In addition to long-running services, containers can be used as standalone task containers (e.g. K8s cronjobs), triggered by functions, and used when the processing time exceeds a reasonable function run-time.
Serverless does not make “DevOps redundant”
It would be great if it did, but for the most part, it does the opposite. The serverless architecture leads to functions’ code being distributed across many repositories. The tracking, monitoring, maintaining, and other operational aspects become tedious and much more complex. This requires creative solutions, or more time-consuming manual labor. Both result in greater engineering effort. In that regard, serverless usually isn’t as promising as it sounds. Quite the contrary, in fact. In the future, a new tool or project may solve this complexity and provide a cross-functional solution. Serverless.com may carry this torch. We’re pretty much where we started in terms of hidden operations, and there’s still a long way to go until we can “abandon” Ops.
Thank you for reading
Serverless functions are an excellent platform if you take the considerations listed above into account. I hope this helps someone out there, and invite you to correct me if you find any inaccuracies.


