After a long while of researching for information on a solution I knew I wanted, it was quite hard to figure out what to choose, and how to use it. And so, this is basically the guide I wish I had: what I wanted and why, the solution itself, and just as important - how to implement a solution that’s well designed, but poorly documented…
What
With the rise of Google’s beyond-corp approach, the concept of “Zero Trust” brought the Identity Aware Proxy to the world. In a nutshell, internal resources or tools sit in private inaccessible areas of the cloud, while a reverse proxy on top of them, offers access to permitted users only. The authentication often relies on an OAuth2 provider, but any kind of user directory does the trick.
Why
Rarely do you enjoy a combination of more than two of these:
- Security
- Quality user experience
- Ease of management / maintenance The magic lies with benefiting from all of the bove with the same solution.
Security
The key feature in an identity-aware proxy is the redundancy of VPN servers. VPN by its nature offers a single point of access to the internal network. Once authenticated, the user has the keys to the kingdom; all internal systems are reachable. In some cases, when RBAC is correctly implemented, authentication is still in the way and protects user access. However, the system is still accessible network-wise, making it susceptible to scans and attacks that might bypass the standard access point.
With a reverse proxy, before the request is being authorized, all access is blocked as the routing didn’t take place. The request was blocked before being rerouted forward.
Another aspect of security comes from the fact that the user has one identity source to manage. If MFA / 2FA has been enabled (and it should!!!), it stands for all future user authentication methods. More on that on the ease of access, and, ease of management.
One clarification before moving on though; this is not to say that VPNs are the past, or that’s something is broken with the concept of having one. Deployed correctly, VPN servers are incredible at what they do. They’re ubiquitous for a reason. That said, most implementations lack basic access control, and those that do, more often than not, do not monitor internal queries once a user has been authenticated. In some cases, there are usually not too many alternatives. But for others - e.g. back-office web services, we can do better.
Ease of access
This is the more straightforward aspect of things; a user with the organization directory only has to manage one identity. Assuming the user is keeping their passwords safe with something like 1Password, and a mandatory 2 step verification, it makes everyone’s life easier. The cookie generated from one successful authentication can be used to access all other systems under the proxy (given the user is permitted to do so).
Ease of management
One of the key pain points engineering / IT / Ops teams struggle with is user management when multiple systems and tools are involved in the development. Instead of managing a growing number of directories and user sets, SSO offers a single point of authentication, allowing the management of only one directory. All that’s left is to integrate SSO with the identity-aware-proxy to leverage both a single access point and the reuse of a cookie.
SSO to the rescue!
While Buzzfeed’s SSO is simply wonderful in terms of concept and implementation, its docs are somewhat incomprehensive for the lack of a better word. The issue amplifies when trying to deploy on ECS Fargate. (Somewhat surprising given the nature of Buzzfeed’s workload on ECS but 🤷).
The How
With that in mind, here’s a guide / better-docs for implementing a “Zero-trust proxy with SSO and cookie reuse on ECS Fargate”
Probably the world record for the single line title with most buzzwords ever…
-
Buzzfeed’s SSO is an implementation of two proxy entities, one service as a proxy to underlying systems and the other as an auth provider. The reason for the local auth provider is being able to serve one login for all systems, instead of having to re-authenticate with every different upstream. This is a cookie-reuse for the same purpose, which is a super elegant solution on behalf of Buzzfeed. Here’s a complex, yet comprehensive visual diagram of the system
-
As said, the system comprises of a proxy and an auth provider, namely
sso-proxyandsso-authenticator(orsso-authin short). Both systems are configured by a set of environment variables, where the backend routing is described in an upstream Yaml config file. With growing usage, additional features, switches, parameters, and updates the project kind of grew out of basic understandable configuration docs. This is why we’re here today.
The Proxy
This is the entity that serves as the front gate for incoming requests. If the incoming request is identified as valid, the request goes through and is routed based on upstream_configs.yml. Otherwise, requests are redirected to the authenticator.
I’ve chosen to build the container image with the environment wrapping Buzzfeed’s image. This is for convenience only and can be shifted to any other method. Building the image with docker build --build-arg client_id=xxx client_secret=xxx ...
FROM buzzfeed/sso
ARG client_id \
client_secret \
session_cookie_secret
ENV UPSTREAM_CONFIGFILE="/sso/upstream_configs.yml" \
UPSTREAM_CLUSTER="" \
PROVIDER_URL_EXTERNAL="https://sso-auth.domain.co" \
CLIENT_ID=$client_id \
CLIENT_SECRET=$client_secret \
SESSION_COOKIE_SECRET=$session_cookie_secret \
SESSION_TTL_LIFETIME="1h" \
UPSTREAM_SCHEME=http
COPY ./upstream_config.yml /sso/upstream_configs.yml
ENTRYPOINT ["/bin/sso-proxy"]
The Authenticator
Receiving unauthenticated requests from the proxy, the authenticator is in charge of contacting the OAuth2 provider for authorization. According to configuration, if the requesting user has the relevant permissions i.e. authorized domain, correct sub-group, and so on, a cookie is set and redirected to the proxy, which in turn lets it through.
Built-in the same manner as its twin, the authenticator is based on the same image, only uses a different ENTRYPOINT and a different set of configuration variables:
FROM buzzfeed/sso
ARG client_id \
client_secret \
session_cookie_secret \
session_key
ENV AUTHORIZE_EMAIL_DOMAINS=domain.co \
AUTHORIZE_PROXY_DOMAINS=domain.co \
SERVER_HOST=sso-auth.domain.co \
CLIENT_PROXY_ID=$client_id \
CLIENT_PROXY_SECRET=$client_secret \
SESSION_COOKIE_SECURE=true \
SESSION_COOKIE_SECRET=$session_cookie_secret \
SESSION_COOKIE_EXPIRE=1h \
SESSION_KEY=$session_key \
PROVIDER_X_CLIENT_ID=$client_id \
PROVIDER_X_CLIENT_SECRET=$client_secret \
PROVIDER_X_TYPE=google \
PROVIDER_X_SLUG=google \
PROVIDER_X_GOOGLE_IMPERSONATE=admin@domain.co \
PROVIDER_X_GOOGLE_CREDENTIALS=/sso/credentials.json \
PROVIDER_X_GROUPCACHE_INTERVAL_REFRESH=1m \
PROVIDER_X_GROUPCACHE_INTERVAL_PROVIDER=1m \
LOGGING_LEVEL=debug
COPY ./credentials.json /sso/credentials.json
EXPOSE 4180
ENTRYPOINT ["/bin/sso-auth"]
OAuth2 Provider of choice - Google
Not much to elaborate on Google. It’s workspace directory offers a wide range of user management feature and is considered a standard choice. Specifically Buzzfeed’s SSO offers either Google or Okta as providers. If these are not the way your organization is managing user this post might be irrelevant for the most part. You can however, make use of the underlying system - OAuth2-proxy, which will provide a similar experience, except the solution of a single locally managed authentication mechanism. Instead of having two components, the proxy is one system that operates against the backend provider.
Instructions (although far from perfect) can be found here. Important notes:
- Please do go through all steps, even if some seem unnecessary; like not following step three and forward if group segregation is not a requirement. Do go all the way through it, and make sure you get the .json file at the end.
- Read carefully, make sure admin SDK is enabled as shown
- Make sure that from Google’s worskspace security side, the API controls
- Make sure the
PROVIDER_X_GOOGLE_IMPERSONATE=admin@domain.cois set with an admin user
Upstreams
Upstreams are a configuration file where proxy routes are set. They take a public request form the web, and, if authenticated is routed to an internal (or not) service given some conditions are met.
The configuration below describes two services and their internal routes:
- service: vault
default:
from: vault.sso.domain.co
to: vault.local:8200
options:
allowed_groups:
- production@domain.co
- service: snappass
default:
from: secrets.sso.domain.co
to: secrets.local:5000
options:
allowed_email_domains:
- domain.co
Notes:
- Each entry must have a
defaultsetting, other custom settings can follow from&toare the base, whileoptionsare optional only if one of the top threeUPSTREAM_DEFAULT_are set. I’ve learned this one the hard way…- Note how
allowed_groupsorallowed_email_domainsare set and sufficient on their own. The first is permitting access for a specific directory group, while the latter offers a domain wide access with - The entire set of
optionscan be found here
Deployment
The two services above should be deployed together in an internal network just as any other service would. The best practise here dictates a load balancer on top, to route traffic into the proxy / authenticator. The only thing to consider here is the reachability of upstream services; a system that’s considered “internal” and will be accessed through the proxy has to be accessible from the proxy itself. On the network level, this means that they either have to sit in the same virtual private network, or have a peering between the networks. From the proxy’s perspective, the IP and the port should be in-reach and open. “Open” also means that they would be part of the same security group, or open a rule in the respective groups to be able to provide back and forth communication.
ECS and Service Discovery
Once the proxy is set, the user gains access, they should be able to communicate with endpoints only accessible internally within the private network, the VPC. While we can redirect the request to an IP, those tend to change and the connection is then lost. An improvement can be an elastic IP that’s guaranteed to stay fixed with the resource it was attached to. This brings a few new issues though; a. the resource itself can (and should) be rotated within time - we are dealing with containers after all. b. Elastic IPs will start being charged once their underlying resource no longer exists. Another improvement might be a human-readable DNS A record that’s pointed at the same IP. Still, being readable and all, the inherent problem with a static IP remains.
The solution - AWS Service Discovery. Put simply, the service discovery service attaches itself to an ECS target group, updating the live running tasks underneath with an internal endpoint managed by Route53. Meaning, the user can hit the same endpoint and trust it to resolve to a dynamic IP that’s connected to an existing task.
Here’s a quick example using Terraform code (out of convenience only - this can be set manually or using any other language):
A global resource of private dns namespace has to be crated first, before it can host internl records:
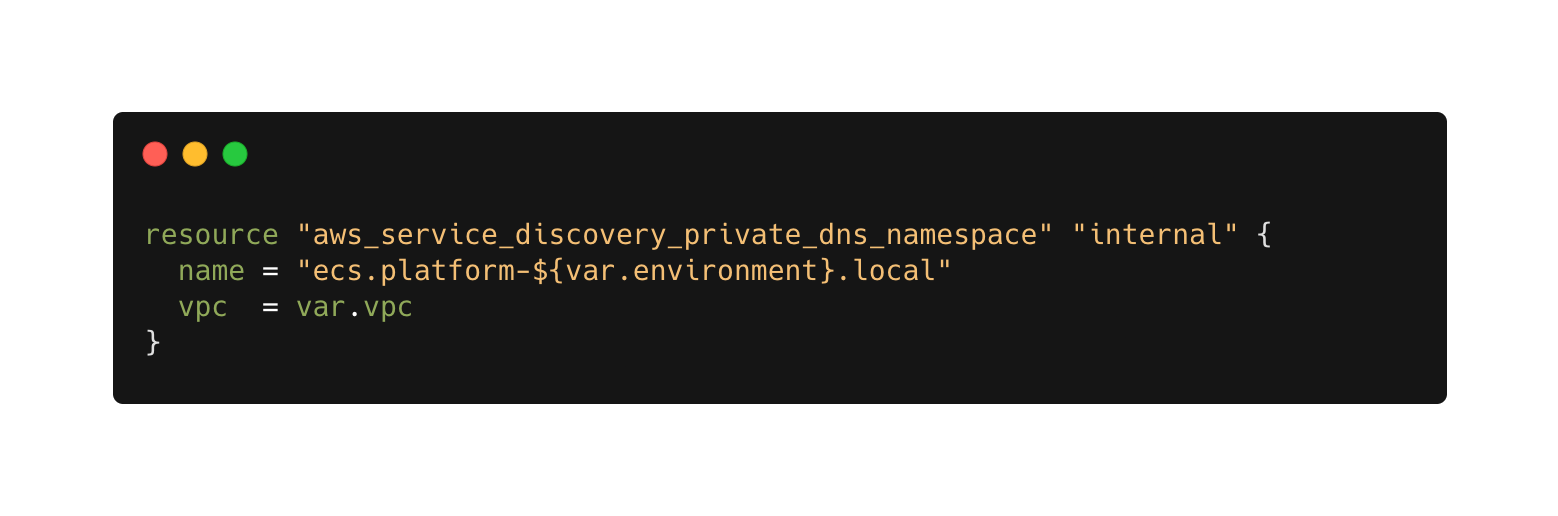
After the namespace is ready, we can start creating private records, note the reference to the namespace inside dns_config:
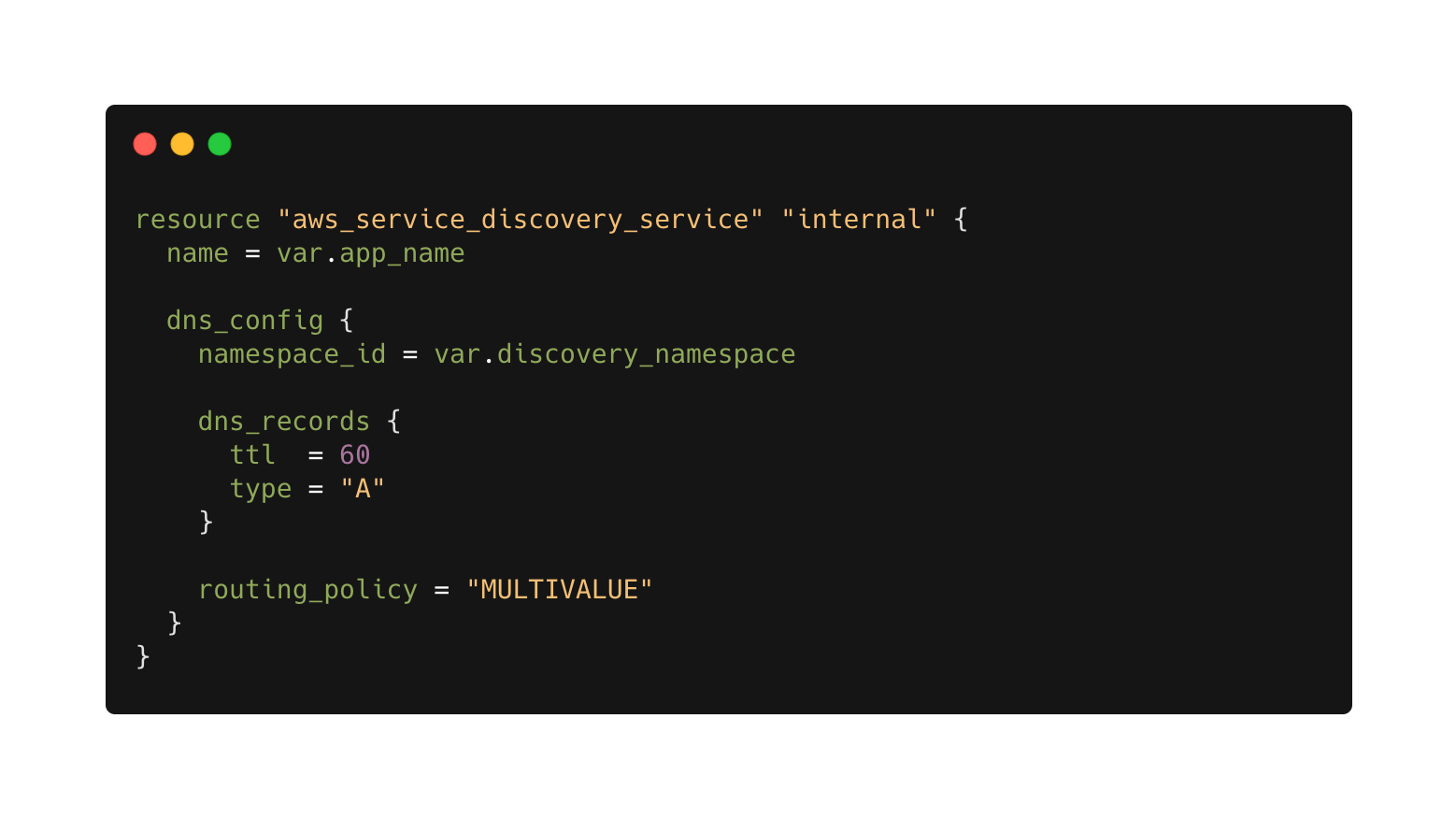
And lastly, connecting the aws_ecs_service resource to the service registry:

Alternatives
The solution above is no the only one for zero trust solution. There are plenty out there, including commecrial ones as well as many OSS alternatives. Buzzfeed’s solution was the choice here for its elegance by remaining a one-stop authentication system that builds on top of Google’s OAuth2 solution. Any kind of solution will usually do pretty much the same work, and as long as the concept of security is kept, the rest is implementation details.
Extending the power of Zero Trust
Having the system deployed is a great solution for all things web. But sometimes real-life pop the security bubble; in some cases engineers will need to gain access to private resources by SSH, or other protocols (working aginst a Redis or a PostgreSQL instance). While Working directly against a resource in its protocol is not achievable, we can extend the reach by deploying web interfaces for SSH, PGAdmin-like applications.
I would address the engineering culture of accessing private resources in the first place, and how to create a workflow that removes the necessity of such operations, but that’s material for another post. In the meantime, let’s leave the notion of avoiding it when you can. And if you’re serious, you may consider rotating those accessed instances altogether, marking them as contaminated once they’ve been SSH’ed into and automating their removal. Food for thought…
I hope this post helped with grasping the concept of zero trust and a real world implementation. This is some I struggled with when I tried incorporating it in our workflow, so I’m happy to share the experience and the “how to”.
If you find any mistakes in the information above, have any questions or comments please reach out!
Thank you for reading 🖤



{kind=link}