Kill waste. Focus. Innovate. Stay Lean. Be a pro.
 You can’t afford to do anything but win
You can’t afford to do anything but win
The success rate of startups in 2017 was 2.5%. According to last year’s statistics, 75% of US venture-backed startups fail. “Success” being translated to reaching the point of a successful sale. Obviously, the interpretation is objective, but the general idea is similar. Let’s address the more interesting insights; 97.5% of the ideas fail to make it to a “success” point. Without dwelling too much on the interpretation, I’d like to offer another angle to the story — operations; software operations.
Ops / DevOps / SRE and Production engineering are all fancy names to software operations. The very field that defines automation processes development for building, testing, delivering, monitoring, building resilient infrastructure, sometimes even experimenting with chaos and more.
Most startups (and by startups I’m referring to any team of ≥ 1 human beings with an idea and one written line of code) are probably not even considering the idea of implementing any component of the fields above. Scary terms like “resiliency”, “automation” and “scale” sound like they come from the terminology world of Giants like Netflix or Facebook —
I beg to differ. Here’s why:
If you have a great idea, already carved a plan, maybe even practiced some pitching and basically started working, you should be focusing on developing your product and doing that alone. Allow me to assume your company isn’t already funded and backed by a management board (in which case these ideas are not even a considerable suggestion, but an urgent must), and as such you don’t have the luxury of wasting… Anything.
If in the process of developing your product, you **manually **did one or more of:
-
Tests Triggering
-
Code building
-
Container building / publishing
-
Recurring dependency installation
-
Recurring environment creations and configurations
-
Reporting to the team on a new release / build / tests runs
-
Application deployment
-
Or Any other recurring work
You are wasting your time, Literally!
Sound familiar? Don’t get caught up, change direction and move forward. Easier said than done, but very much doable. It doesn’t matter whether you are a team of one developer or even managing a remote entity to develop the product, certain decisions are required from day one of work. It’s not trivial, but it is very much essential to the productivity of your team, and for the chances of breaking out and making your product rise above others.
Take a breath
My suggestion is not easy to adopt, but please hear (read) me out: Take a week worth of your R&D team work, even if it consists of a single developer, and invest it in building and setting up tools for automation, delivery pipeline and monitoring. Yes, “Continuous Integration” is not a scary buzzword, you don’t need to hire experts or pay tons of $$, you can do it in a single afternoon. If you decide to put a day into it, you’ll even get the benefits of a system that will suffice for a few good years to come, scout’s honor.
Make sure the entire team takes the week and focuses it’s resources for this one purpose; the time spent and scale of productivity will naturally result in tools and processes reflecting the size of your team and it’s requirements. Everyone will be onboard and share a sense of responsibility over the systems built during the week.
In order to illustrate the idea of automating operations and its affect on dev teams, consider these two models of team progress. Which one do you want be on?
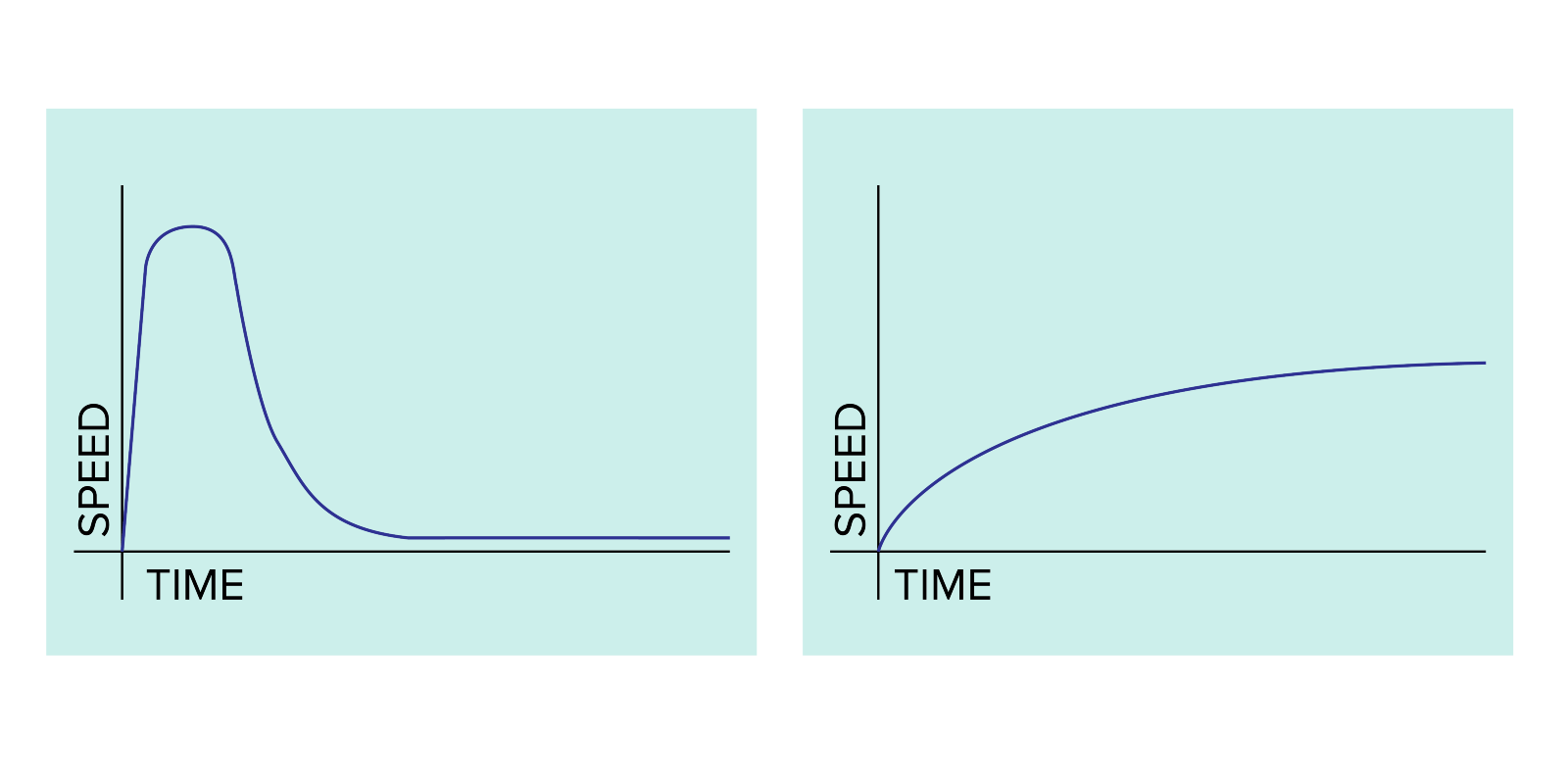 Team speed over time; plan right, and you can make sure you never slow down
Team speed over time; plan right, and you can make sure you never slow down
Got extra cash to use and want to save expensive time? Travis, CircleCI and my personal favourite- Drone, all have a SAAS service ready to roll so that the solution is managed, deployable in minutes, and takes the pain of operations away.
Deliver
Got your CI server ready to run? Great, take some time and build your delivery pipeline: plan builds, tests and deployments, so that your application would automatically flow through each of these steps independently with every push or merge request. Make sure results that require reporting like failed tests or unavailable services are being reported directly by email or the favourite messaging app of your choice. * Personal recommendation: Slack FTW.
Test
Do TDD! This cannot be stressed enough, investing in a good testing suite and letting it lead the way, would not only save time and energy, but also future frustration and all-nighters of debugging. This goes hand in hand with your already-designed pipeline of building, testing, reporting and deploying. Where a product is throughly tested, automation thrives (and as a side-effect, developers too 😉).
Log
Design your application to produce verbose and meaningful logs. Report application activity and behaviour. Separate to different log levels and try to provide a useful structure like a constant JSON scheme. Think about the near future when some kind of ELK will start playing a role, allowing you to analyze any part of your application simply by reading shards of logs, and extracting the exact fields that were already indexed, thanks to your first week of work!
Analyze
Log analysis can wait, but make sure you understand what’s at stake before deciding whether you allocate the resources in the scope of this week.
What if you could start playing with your logs, instead of plainly reading them one by one? → Elastic provides a SAAS solution for ELK but you can do just the same with AWS CloudWatch, GCP Stackdriver or the feature-packed alternatives like Coralogix or Logz.io. Each providing his own benefits, and a managed solution that can be set up in hours. Do: Collect your logs and store them centrally, whether it’s Logstash or S3, etc. Do not: Leave logs on machines / containers and SSH to read them. Not only will you compromise your resources while SSHing, this method of debug and analysis is not sustainable. Use an external service or a central storage at the least.
Bottom line: Do it. It won’t be two weeks before you’ll start enjoying the benefits of speaking the same language your product does; being able to practically ask questions and receive insightful answers, like:
-
“How much UsernameError exceptions were thrown during our last major incident?”
-
“How many CRITICAL log messages are seen on average during a 24 hour period?” → “Generate a monthly graph showing the results” → “Locate anomalies, isolate and extract the errors from these exact periods”
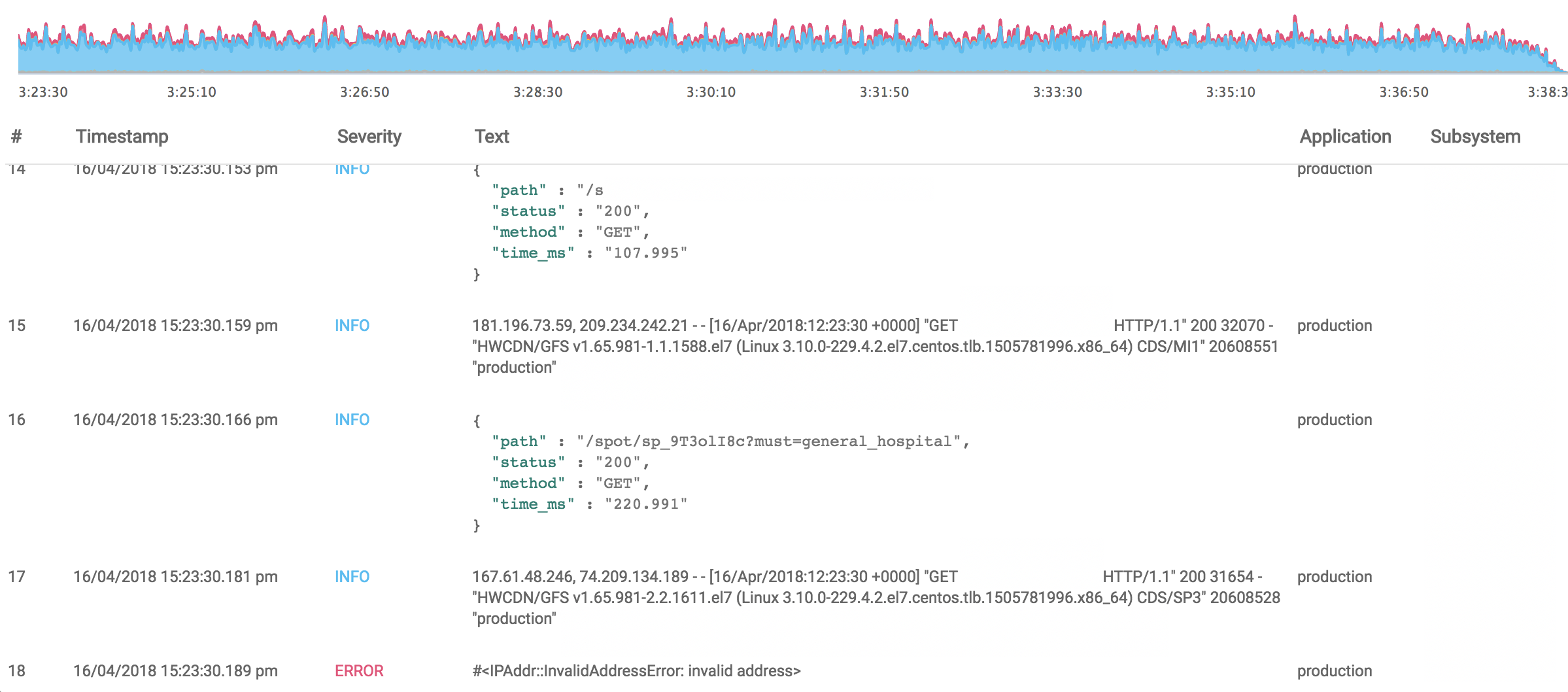 Log analysis broken down by Application, Severity, Time or any other parameter required
Log analysis broken down by Application, Severity, Time or any other parameter required
Monitor
Know what your application is going through at all times. Measure as much relevant metrics as possible to be able to debug, respond and improve quickly and in short cycles. Knowing how your application behaves is crucial; you need to be aware of CPU intensity, memory consumption and leaks, as well as latency of requests and levels+nature of errors. You do not need a gigantic monitoring platform, you can start small with managed solutions by your favourite cloud provider, e.g AWS CloudWatch metrics. If you’re cloud-based, everything is already collected for you, all you have to do is pick it up: invest a couple of hours and choose what you would like to be visibly aware of. Short on time? **Set up a service like RunScope or PingDom, which would be super easy to deploy, and constantly measuring your service/s health. You may not know the bits and bytes of every problem, but at least you’ll be aware. **Got extra time? Use Prometheus which will collect applicative metrics, and then view in a tool such as Grafana. This couple will provide a more in-depth and customized visualization possibilities, which will be able to scale into any size of production resources, and deal with future application metrics. Or: deploy a plugin based monitoring tool like Sensu and use it either with installed agents (push) or probing the services for information (pull).
*Got extra cash? **Take NewRelic / DataDog / any other application monitoring solution for a test drive. The things you’ll learn about your application will deeply influence the quality of your development process, and as a result — *the quality of your product.
Bottom line: Even if you start lean, start with the basics, know your systems’ metrics. In most cases they are already collected, just organize and monitor.
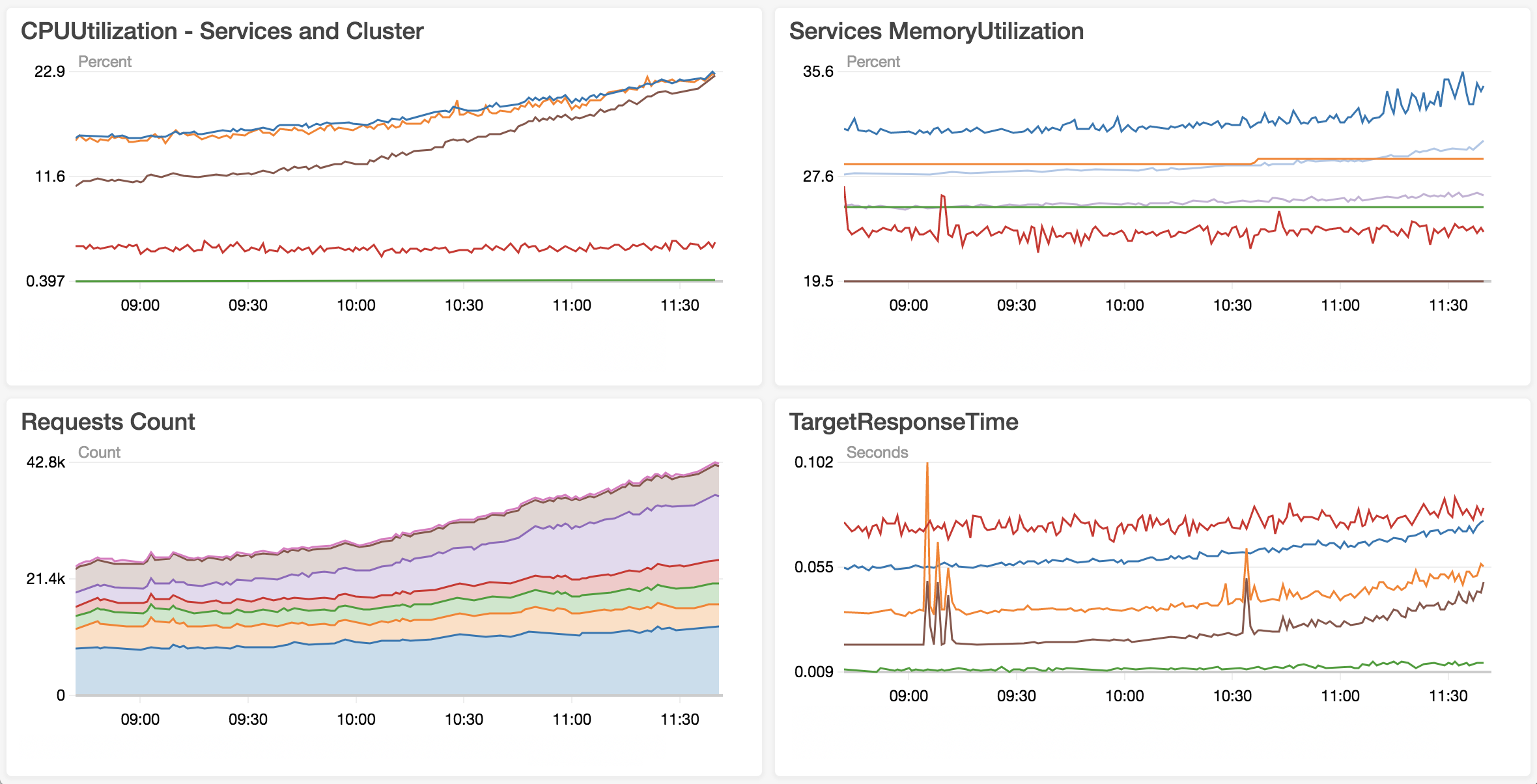 “Know what you application is going through at all times”
“Know what you application is going through at all times”
Alert
Based on your already-collected metrics, set alerts to points where certain thresholds are crossed and notify yourself / your dev team. Knowing exactly when something goes wrong, doesn’t only save you in production. Even if you’re still developing your product, you’ll be able to catch errors as they happen, ease the process of debugging and history searching and keep improving in short cycles of feedback. Again, in most cloud platforms, since you already got the metrics collected for you, all that’s left is to set the alarms and notifications, e.g AWS CloudWatch Alarms. Use Slack (or equivalent): Integrate bots and incoming web-hooks to send as much as possible incoming data from your systems — alerts, notifications, reports — present them all in one place that’s easy to read and track. Prevent alert fatigue by applying logic on when to alert and how.
**Got extra cash? **Add a product like VictorOps / OpsGenie / PagerDuty for reporting, on call shifting, team reporting management and escalation policies. Even if you don’t utilize their entire feature set, you’ll be able to be informed and respond to issues as they happen, and share them with the rest of the team.
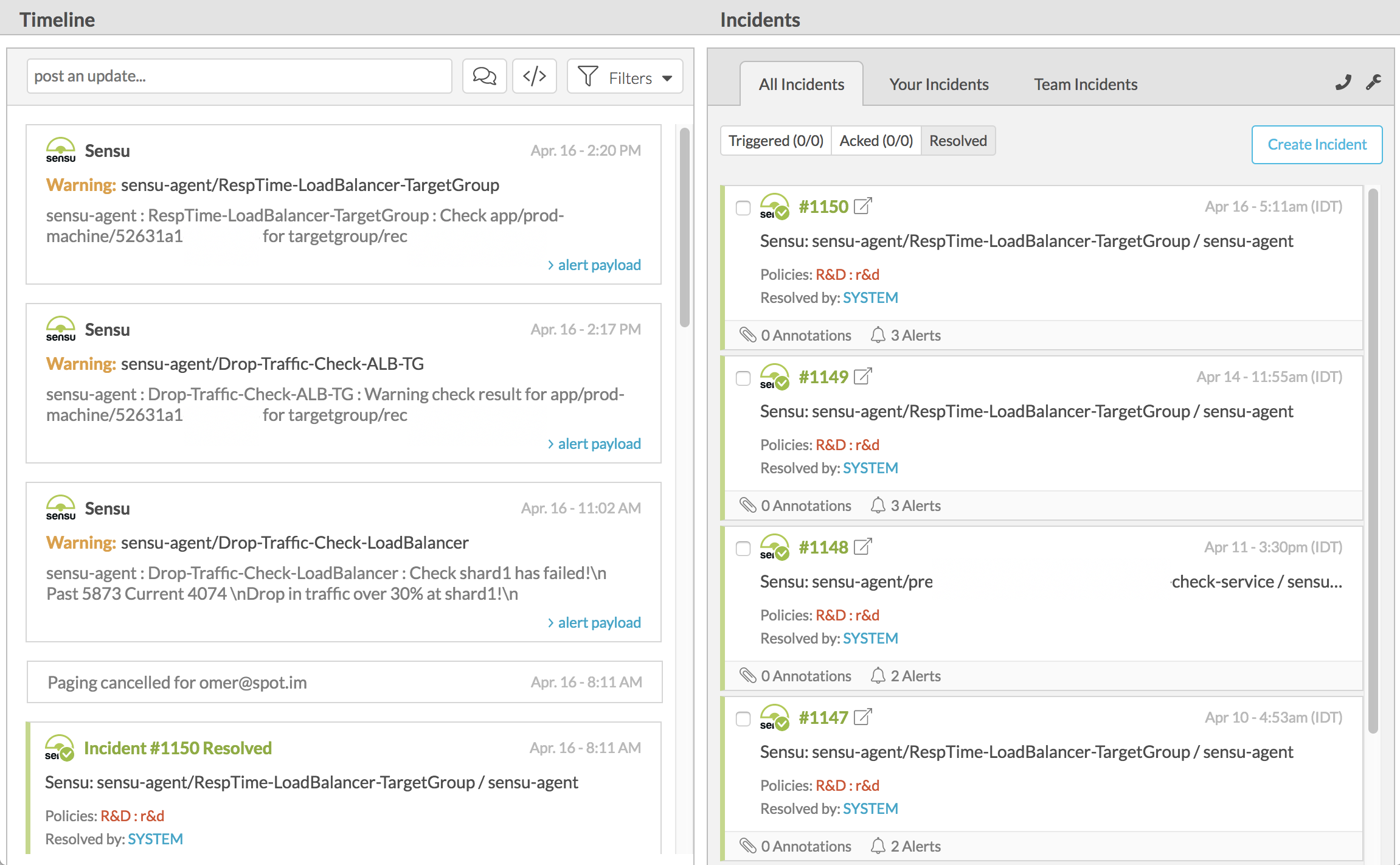 An example alerting dashboard for VictorOps, being triggered by Sensu
An example alerting dashboard for VictorOps, being triggered by Sensu
Communicate
At the end of the day, “DevOps” is all about communication. Being able to deliver ideas, break silos, collaborate and reach common grounds are all the building blocks for making dev and ops work together. Building communication between teams is not an easy task. Hell, even between two people you can sometimes get lost.
WhatsApp or Telegram are nice for private chats or discussions, but your plans, tasks, and work related chats should be contained in a searchable structure that’s easy to work with. Reduce emails: Use a communication app like Slack to create different discussion channels, share documents, designs, logos, links and everything related to a certain topic, so that you’re able to come back to and find it easily.
Plan and collaborate on one central place. Use a product like Atlassian’s Jira to manage sprints, tickets, projects and overall timeline and progress.
- Pro tip — Connect your planning product to Slack as well to keep track on tickets; moving, creating and updating them without ever logging into the system.
Wrapping things up
With a week of work you can achieve all of the above, and even more with some motivation. Although they seem somewhat distant and irrelevant to your product’s phase, these set of tools and platforms will not only boost your development speed, it will make your entire process fluent, responsive and fun to work with. It would save tons of hours of recurring work, debugging and searching. You’ll become proactive and on top of the system instead of the other way around. Planning to grow? On-boarding of a new engineer takes a lot of unproductive time of him and his guide. Automated systems would take half the time to explain and on-board, while preventing expected mistakes.
Most of the solutions above would be free of charge to a certain extent, the rest would cover their costs within one month of operation, guaranteed.
Even if you are a team of one developer, and maybe especially if you are alone in the battle: having a supportive ecosystem of tools will help you constantly manage and improve the quality of your product. You’ll be completely killing waste, which will allow you to focus on the one thing you should — innovation.
Disclaimer: I’ve mentioned many tools in this post, all of them are based on personal experience. Take responsibility on your choices, make your own research before adopting any of them to production. But more important than that; keep in mind that the process is not about tools or names, it’s about ideas and methodologies. Be focused on your idea, be methodological in your work and always plan. Good luck on your journey!
My name is Omer, and I am an engineer at ProdOps — a global consultancy that delivers software in a Reliable, Secure and Simple way by adopting the Devops culture. Let me know your thoughts in the comments below, or connect with me directly on Twitter @0merxx. Clap if you liked it, it helps me focus my future writings!

This story is published in The Startup, Medium’s largest entrepreneurship publication followed by 318,983+ people.
Subscribe to receive our top stories here.



